A Deadly Mistake Uncovered on Deepseek And Find out how to Avoid It
페이지 정보

본문
 The DeepSeek LLM’s journey is a testament to the relentless pursuit of excellence in language models. Model particulars: The DeepSeek fashions are skilled on a 2 trillion token dataset (split across principally Chinese and English). R1 is significant because it broadly matches OpenAI’s o1 mannequin on a spread of reasoning tasks and challenges the notion that Western AI companies hold a big lead over Chinese ones. On C-Eval, a consultant benchmark for Chinese instructional data analysis, and CLUEWSC (Chinese Winograd Schema Challenge), DeepSeek-V3 and Qwen2.5-72B exhibit comparable performance ranges, indicating that each models are nicely-optimized for difficult Chinese-language reasoning and instructional duties. Best results are proven in bold. To be specific, throughout MMA (Matrix Multiply-Accumulate) execution on Tensor Cores, intermediate results are accumulated utilizing the limited bit width. However, on the H800 architecture, it is typical for 2 WGMMA to persist concurrently: whereas one warpgroup performs the promotion operation, the opposite is ready to execute the MMA operation. It is worth noting that this modification reduces the WGMMA (Warpgroup-level Matrix Multiply-Accumulate) instruction subject fee for a single warpgroup.
The DeepSeek LLM’s journey is a testament to the relentless pursuit of excellence in language models. Model particulars: The DeepSeek fashions are skilled on a 2 trillion token dataset (split across principally Chinese and English). R1 is significant because it broadly matches OpenAI’s o1 mannequin on a spread of reasoning tasks and challenges the notion that Western AI companies hold a big lead over Chinese ones. On C-Eval, a consultant benchmark for Chinese instructional data analysis, and CLUEWSC (Chinese Winograd Schema Challenge), DeepSeek-V3 and Qwen2.5-72B exhibit comparable performance ranges, indicating that each models are nicely-optimized for difficult Chinese-language reasoning and instructional duties. Best results are proven in bold. To be specific, throughout MMA (Matrix Multiply-Accumulate) execution on Tensor Cores, intermediate results are accumulated utilizing the limited bit width. However, on the H800 architecture, it is typical for 2 WGMMA to persist concurrently: whereas one warpgroup performs the promotion operation, the opposite is ready to execute the MMA operation. It is worth noting that this modification reduces the WGMMA (Warpgroup-level Matrix Multiply-Accumulate) instruction subject fee for a single warpgroup.
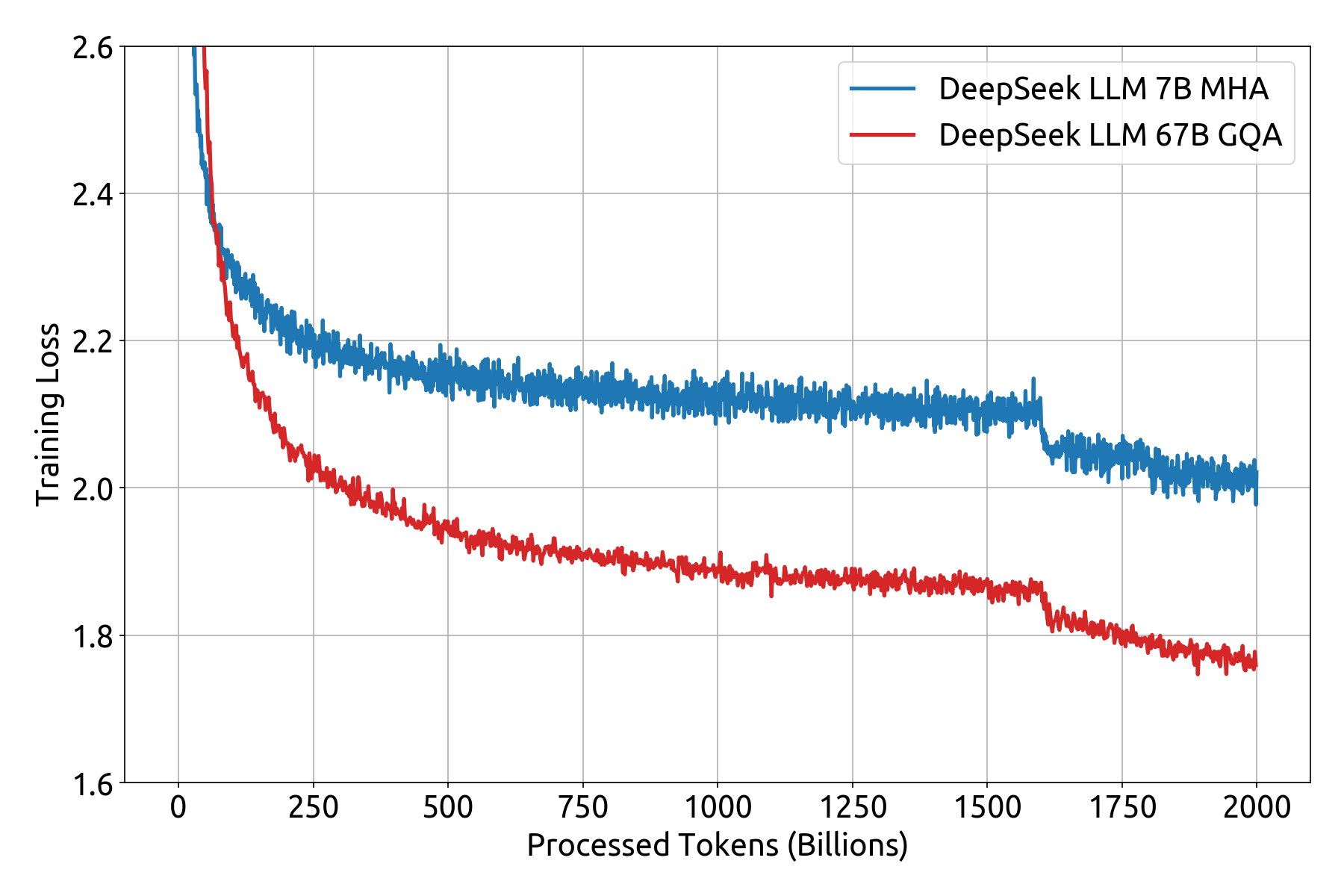 This significantly reduces the dependency on communication bandwidth in comparison with serial computation and communication. This considerably reduces memory consumption. • Transporting information between RDMA buffers (registered GPU reminiscence areas) and enter/output buffers. To realize load balancing among completely different specialists in the MoE part, we need to ensure that each GPU processes approximately the same variety of tokens. Shawn Wang: At the very, very primary stage, you want data and also you want GPUs. However, we do not must rearrange consultants since every GPU solely hosts one skilled. Within the decoding stage, the batch dimension per expert is relatively small (normally inside 256 tokens), and the bottleneck is memory entry somewhat than computation. Much like prefilling, we periodically decide the set of redundant consultants in a certain interval, primarily based on the statistical knowledgeable load from our on-line service. Unlike prefilling, attention consumes a bigger portion of time within the decoding stage.
This significantly reduces the dependency on communication bandwidth in comparison with serial computation and communication. This considerably reduces memory consumption. • Transporting information between RDMA buffers (registered GPU reminiscence areas) and enter/output buffers. To realize load balancing among completely different specialists in the MoE part, we need to ensure that each GPU processes approximately the same variety of tokens. Shawn Wang: At the very, very primary stage, you want data and also you want GPUs. However, we do not must rearrange consultants since every GPU solely hosts one skilled. Within the decoding stage, the batch dimension per expert is relatively small (normally inside 256 tokens), and the bottleneck is memory entry somewhat than computation. Much like prefilling, we periodically decide the set of redundant consultants in a certain interval, primarily based on the statistical knowledgeable load from our on-line service. Unlike prefilling, attention consumes a bigger portion of time within the decoding stage.
Additionally, to reinforce throughput and cover the overhead of all-to-all communication, we're additionally exploring processing two micro-batches with similar computational workloads concurrently in the decoding stage. Additionally, these activations will likely be transformed from an 1x128 quantization tile to an 128x1 tile in the backward go. Notably, our fine-grained quantization strategy is extremely in line with the thought of microscaling formats (Rouhani et al., 2023b), while the Tensor Cores of NVIDIA subsequent-generation GPUs (Blackwell series) have announced the help for microscaling codecs with smaller quantization granularity (NVIDIA, 2024a). We hope our design can serve as a reference for future work to keep pace with the most recent GPU architectures. free deepseek-R1 collection support business use, allow for any modifications and derivative works, including, however not limited to, distillation for training other LLMs. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the neighborhood. But what DeepSeek prices for API access is a tiny fraction of the cost that OpenAI costs for entry to o1.
Nobody has independently verified that DeepSeek isn’t utilizing large compute sources to achieve its benchmark results (or has not basically copied OpenAI), however U.S. POSTSUBSCRIPT is reached, these partial outcomes will be copied to FP32 registers on CUDA Cores, where full-precision FP32 accumulation is performed. Although the dequantization overhead is significantly mitigated mixed with our precise FP32 accumulation technique, the frequent knowledge movements between Tensor Cores and CUDA cores still limit the computational effectivity. Despite the efficiency advantage of the FP8 format, certain operators nonetheless require the next precision as a consequence of their sensitivity to low-precision computations. As illustrated in Figure 6, the Wgrad operation is carried out in FP8. Before the all-to-all operation at every layer begins, we compute the globally optimal routing scheme on the fly. However, this requires extra cautious optimization of the algorithm that computes the globally optimal routing scheme and the fusion with the dispatch kernel to reduce overhead. We focus the bulk of our NPU optimization efforts on the compute-heavy transformer block containing the context processing and token iteration, wherein we employ int4 per-channel quantization, and selective mixed precision for the weights alongside int16 activations. ×FP8 multiplications, no less than 34-bit precision is required.
Here is more information regarding ديب سيك take a look at our site.
- 이전글This Is The Ultimate Guide To Renault Megane Key Card Replacement Cost 25.02.01
- 다음글How To Beat Your Boss Local Car Locksmith 25.02.01
댓글목록
등록된 댓글이 없습니다.
