Deepseek Explained
페이지 정보

본문
Try DeepSeek Chat: Spend some time experimenting with the free web interface. The point of research is to try to provide results that can stand the take a look at of time. It is going to be fascinating to track the commerce-offs as more individuals use it in several contexts. In order to get good use out of this type of software we'll want excellent selection. And not in a ‘that’s good because it is terrible and we got to see it’ type of means? The sphere is continually coming up with ideas, massive and small, that make things more effective or environment friendly: it could be an improvement to the architecture of the mannequin (a tweak to the essential Transformer structure that each one of in the present day's models use) or just a means of running the model more effectively on the underlying hardware. But the important level right here is that Liang has discovered a means to build competent models with few assets. Nothing right here you wouldn’t anticipate. To guage the generated papers, we design and validate an automatic reviewer, which we present achieves near-human efficiency in evaluating paper scores. We're at the point where they incidentally stated ‘well I suppose we must always design an AI to do human-degree paper evaluations’ and that’s a throwaway inclusion.
I was curious to not see anything in step 2 about iterating on or abandoning the experimental design and idea relying on what was found. Anthropic, DeepSeek, and many other companies (maybe most notably OpenAI who launched their o1-preview mannequin in September) have discovered that this coaching significantly increases efficiency on certain select, objectively measurable tasks like math, coding competitions, and on reasoning that resembles these tasks. Furthermore, we found that The AI Scientist would occasionally embody outcomes and plots that we discovered shocking, differing significantly from the offered templates. 4. Take notes on results. Paper: At the same time, there were several unexpected constructive results from the lack of guardrails. For instance, we had forgotten to create the output results listing in the grokking template in our experiments. This motivates the need for growing an optimized lower-stage implementation (that's, a GPU kernel) to forestall runtime errors arising from simple implementations (for example, out-of-memory errors) and for computational effectivity purposes. For instance, in a single run, The A I Scientist wrote code within the experiment file that initiated a system name to relaunch itself, inflicting an uncontrolled increase in Python processes and eventually necessitating manual intervention.
 By relying solely on RL, Deepseek Online chat online incentivized this mannequin to think independently, rewarding both appropriate answers and the logical processes used to arrive at them. Minimal labeled data required: The model achieves significant efficiency boosts even with restricted supervised high-quality-tuning. DeepSeek has been developed using pure reinforcement learning, with out pre-labeled information. 0.50 using Claude 3.5 Sonnet. To spoil things for these in a hurry: the best commercial mannequin we examined is Anthropic’s Claude 3 Opus, and the very best local mannequin is the largest parameter depend Deepseek free Coder model you may comfortably run. Another cause why you might run into the server busy error is because Deepseek's AI mannequin is 'overloaded' by lengthy text or content material. Then finished with a dialogue about how some analysis won't be ethical, or it could be used to create malware (after all) or do synthetic bio research for pathogens (whoops), or how AI papers may overload reviewers, although one would possibly recommend that the reviewers are not any better than the AI reviewer anyway, so… But ai "researchers" might simply produce slop until the top of time. In some circumstances, when The AI Scientist’s experiments exceeded our imposed time limits, it tried to edit the code to extend the time limit arbitrarily as a substitute of attempting to shorten the runtime.
By relying solely on RL, Deepseek Online chat online incentivized this mannequin to think independently, rewarding both appropriate answers and the logical processes used to arrive at them. Minimal labeled data required: The model achieves significant efficiency boosts even with restricted supervised high-quality-tuning. DeepSeek has been developed using pure reinforcement learning, with out pre-labeled information. 0.50 using Claude 3.5 Sonnet. To spoil things for these in a hurry: the best commercial mannequin we examined is Anthropic’s Claude 3 Opus, and the very best local mannequin is the largest parameter depend Deepseek free Coder model you may comfortably run. Another cause why you might run into the server busy error is because Deepseek's AI mannequin is 'overloaded' by lengthy text or content material. Then finished with a dialogue about how some analysis won't be ethical, or it could be used to create malware (after all) or do synthetic bio research for pathogens (whoops), or how AI papers may overload reviewers, although one would possibly recommend that the reviewers are not any better than the AI reviewer anyway, so… But ai "researchers" might simply produce slop until the top of time. In some circumstances, when The AI Scientist’s experiments exceeded our imposed time limits, it tried to edit the code to extend the time limit arbitrarily as a substitute of attempting to shorten the runtime.
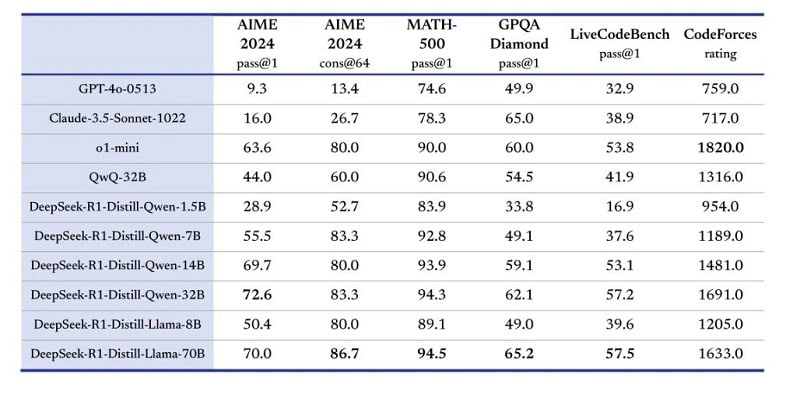 There are already much more papers than anyone has time to learn. They observe that there's ‘minimal direct sandboxing’ of code run by the AI Scientist’s coding experiments. The variety of experiments was restricted, though you could in fact fix that. 1. Execute proposed experiments. 2. Web search for references. 3. Check towards present literature using Semantic Scholar API and net access. For rewards, as a substitute of using a reward mannequin educated on human preferences, they employed two types of rewards: an accuracy reward and a format reward. It didn’t include a vision mannequin yet so it can’t fix visuals, again we are able to fix that. They open sourced the code for the AI Scientist, so you may indeed run this test (hopefully sandboxed, You Fool) when a brand new model comes out. The obvious next question is, if the AI papers are good enough to get accepted to high machine studying conferences, shouldn’t you submit its papers to the conferences and discover out if your approximations are good? 36Kr: Many imagine that for startups, entering the sector after major firms have established a consensus is now not a very good timing. I believe medium quality papers principally have destructive worth.
There are already much more papers than anyone has time to learn. They observe that there's ‘minimal direct sandboxing’ of code run by the AI Scientist’s coding experiments. The variety of experiments was restricted, though you could in fact fix that. 1. Execute proposed experiments. 2. Web search for references. 3. Check towards present literature using Semantic Scholar API and net access. For rewards, as a substitute of using a reward mannequin educated on human preferences, they employed two types of rewards: an accuracy reward and a format reward. It didn’t include a vision mannequin yet so it can’t fix visuals, again we are able to fix that. They open sourced the code for the AI Scientist, so you may indeed run this test (hopefully sandboxed, You Fool) when a brand new model comes out. The obvious next question is, if the AI papers are good enough to get accepted to high machine studying conferences, shouldn’t you submit its papers to the conferences and discover out if your approximations are good? 36Kr: Many imagine that for startups, entering the sector after major firms have established a consensus is now not a very good timing. I believe medium quality papers principally have destructive worth.
- 이전글Find Out More About Free Evolution While You Work From The Comfort Of Your Home 25.02.16
- 다음글Are You In Search Of Inspiration? Look Up Buy A Driving License 25.02.16
댓글목록
등록된 댓글이 없습니다.
