Topic 10: Inside DeepSeek Models
페이지 정보

본문
 DeepSeek itself emerged from High-Flyer’s pivot into AI after the 2021 regulatory crackdown on speculative buying and selling. Why is DeepSeek R1 Getting A lot Attention? Under our training framework and infrastructures, coaching DeepSeek-V3 on every trillion tokens requires only 180K H800 GPU hours, which is way cheaper than coaching 72B or 405B dense fashions. As for Chinese benchmarks, except for CMMLU, a Chinese multi-topic multiple-alternative task, DeepSeek-V3-Base additionally shows higher performance than Qwen2.5 72B. (3) Compared with LLaMA-3.1 405B Base, the biggest open-supply model with eleven occasions the activated parameters, DeepSeek-V3-Base additionally exhibits a lot better efficiency on multilingual, code, and math benchmarks. Reporting by the new York Times offers further proof concerning the rise of broad-scale AI chip smuggling after the October 2023 export control update. Then again, compared to Huawei’s foray into creating semiconductor products and technologies, which is commonly thought of to be state-backed, it appears unlikely that DeepSeek’s rise has been equally state-planned.
DeepSeek itself emerged from High-Flyer’s pivot into AI after the 2021 regulatory crackdown on speculative buying and selling. Why is DeepSeek R1 Getting A lot Attention? Under our training framework and infrastructures, coaching DeepSeek-V3 on every trillion tokens requires only 180K H800 GPU hours, which is way cheaper than coaching 72B or 405B dense fashions. As for Chinese benchmarks, except for CMMLU, a Chinese multi-topic multiple-alternative task, DeepSeek-V3-Base additionally shows higher performance than Qwen2.5 72B. (3) Compared with LLaMA-3.1 405B Base, the biggest open-supply model with eleven occasions the activated parameters, DeepSeek-V3-Base additionally exhibits a lot better efficiency on multilingual, code, and math benchmarks. Reporting by the new York Times offers further proof concerning the rise of broad-scale AI chip smuggling after the October 2023 export control update. Then again, compared to Huawei’s foray into creating semiconductor products and technologies, which is commonly thought of to be state-backed, it appears unlikely that DeepSeek’s rise has been equally state-planned.
 We have explored DeepSeek’s method to the development of superior models. DeepSeek's novel method to AI growth has actually been groundbreaking. We undertake an analogous strategy to DeepSeek-V2 (DeepSeek-AI, 2024c) to allow lengthy context capabilities in DeepSeek-V3. Following our earlier work (DeepSeek-AI, 2024b, c), we adopt perplexity-primarily based analysis for datasets together with HellaSwag, PIQA, WinoGrande, RACE-Middle, RACE-High, MMLU, MMLU-Redux, MMLU-Pro, MMMLU, ARC-Easy, ARC-Challenge, C-Eval, CMMLU, C3, and CCPM, and undertake technology-based evaluation for TriviaQA, NaturalQuestions, DROP, MATH, GSM8K, MGSM, HumanEval, MBPP, LiveCodeBench-Base, CRUXEval, BBH, AGIEval, CLUEWSC, CMRC, and CMath. Within the coaching means of DeepSeekCoder-V2 (DeepSeek-AI, 2024a), we observe that the Fill-in-Middle (FIM) strategy doesn't compromise the subsequent-token prediction capability while enabling the mannequin to accurately predict middle text based mostly on contextual cues. Furthermore, the paper does not discuss the computational and useful resource necessities of coaching DeepSeekMath 7B, which could possibly be a vital issue within the model's real-world deployability and scalability. We curate our instruction-tuning datasets to incorporate 1.5M situations spanning a number of domains, with every domain employing distinct data creation methods tailor-made to its specific necessities. Reference disambiguation datasets include CLUEWSC (Xu et al., 2020) and WinoGrande Sakaguchi et al.
We have explored DeepSeek’s method to the development of superior models. DeepSeek's novel method to AI growth has actually been groundbreaking. We undertake an analogous strategy to DeepSeek-V2 (DeepSeek-AI, 2024c) to allow lengthy context capabilities in DeepSeek-V3. Following our earlier work (DeepSeek-AI, 2024b, c), we adopt perplexity-primarily based analysis for datasets together with HellaSwag, PIQA, WinoGrande, RACE-Middle, RACE-High, MMLU, MMLU-Redux, MMLU-Pro, MMMLU, ARC-Easy, ARC-Challenge, C-Eval, CMMLU, C3, and CCPM, and undertake technology-based evaluation for TriviaQA, NaturalQuestions, DROP, MATH, GSM8K, MGSM, HumanEval, MBPP, LiveCodeBench-Base, CRUXEval, BBH, AGIEval, CLUEWSC, CMRC, and CMath. Within the coaching means of DeepSeekCoder-V2 (DeepSeek-AI, 2024a), we observe that the Fill-in-Middle (FIM) strategy doesn't compromise the subsequent-token prediction capability while enabling the mannequin to accurately predict middle text based mostly on contextual cues. Furthermore, the paper does not discuss the computational and useful resource necessities of coaching DeepSeekMath 7B, which could possibly be a vital issue within the model's real-world deployability and scalability. We curate our instruction-tuning datasets to incorporate 1.5M situations spanning a number of domains, with every domain employing distinct data creation methods tailor-made to its specific necessities. Reference disambiguation datasets include CLUEWSC (Xu et al., 2020) and WinoGrande Sakaguchi et al.
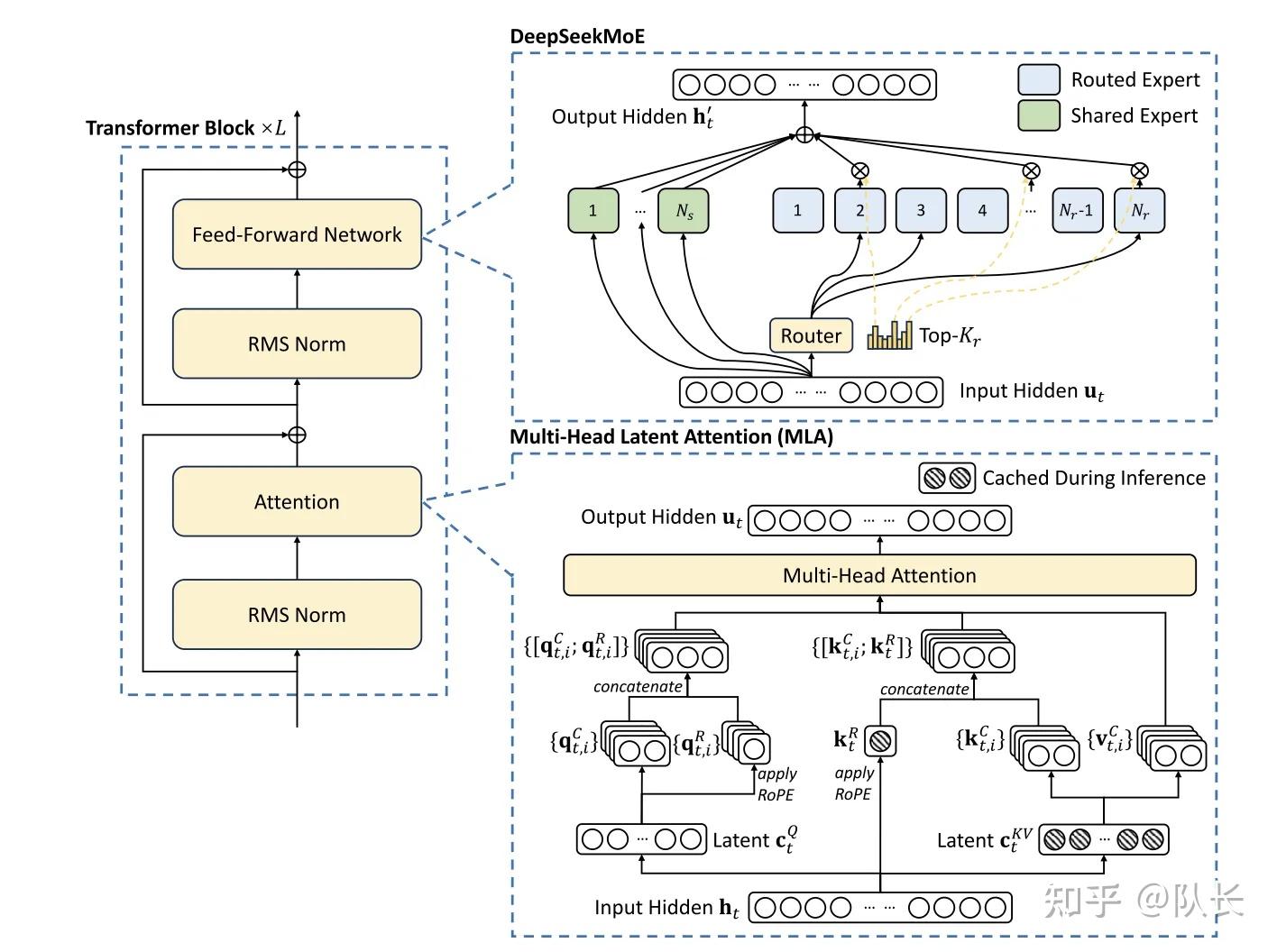
Standardized exams embrace AGIEval (Zhong et al., 2023). Note that AGIEval consists of each English and Chinese subsets. The tokenizer for DeepSeek-V3 employs Byte-level BPE (Shibata et al., 1999) with an extended vocabulary of 128K tokens. As DeepSeek-V2, DeepSeek-V3 additionally employs further RMSNorm layers after the compressed latent vectors, and multiplies further scaling elements on the width bottlenecks. In addition, in contrast with DeepSeek-V2, the new pretokenizer introduces tokens that mix punctuations and line breaks. Their hyper-parameters to control the strength of auxiliary losses are the identical as DeepSeek-V2-Lite and DeepSeek-V2, respectively. Note that during inference, we directly discard the MTP module, so the inference prices of the in contrast fashions are exactly the same. For the second challenge, we additionally design and implement an environment friendly inference framework with redundant professional deployment, as described in Section 3.4, to overcome it. Note that because of the changes in our analysis framework over the past months, the efficiency of DeepSeek-V2-Base exhibits a slight difference from our previously reported outcomes.
The FIM technique is applied at a fee of 0.1, in line with the PSM framework. However, we undertake a sample masking strategy to make sure that these examples stay isolated and mutually invisible. We first consider the speed of masking logits. 2024), we implement the document packing method for knowledge integrity however do not incorporate cross-sample consideration masking during coaching. The experimental results present that, when achieving an analogous level of batch-smart load steadiness, the batch-smart auxiliary loss also can obtain similar mannequin performance to the auxiliary-loss-free technique. This method ensures that the final coaching information retains the strengths of DeepSeek-R1 whereas producing responses which might be concise and effective. The gradient clipping norm is about to 1.0. We employ a batch dimension scheduling technique, where the batch measurement is progressively increased from 3072 to 15360 in the training of the first 469B tokens, after which retains 15360 within the remaining coaching. To validate this, we file and analyze the expert load of a 16B auxiliary-loss-primarily based baseline and a 16B auxiliary-loss-Free Deepseek Online chat mannequin on completely different domains within the Pile take a look at set. In Table 5, we present the ablation results for the auxiliary-loss-free balancing technique. On high of those two baseline models, protecting the coaching knowledge and the other architectures the same, we take away all auxiliary losses and introduce the auxiliary-loss-Free DeepSeek v3 balancing technique for comparison.
If you adored this article and you also would like to obtain more info regarding DeepSeek v3 generously visit our website.
- 이전글3 Ways That The Buy Category C Driving License Can Influence Your Life 25.02.23
- 다음글What Is Double Glazed Window Maidstone And Why Is Everyone Talking About It? 25.02.23
댓글목록
등록된 댓글이 없습니다.
