Eight Best Methods To Promote Deepseek
페이지 정보

본문
 Last week, Free DeepSeek v3 challenged conventional knowledge in AI. DeepSeek can answer questions, resolve logic problems, and write computer programs on par with different chatbots, according to benchmark exams utilized by American AI corporations. Companies can combine it into their merchandise with out paying for usage, making it financially attractive. The case for this release not being dangerous for Nvidia is even clearer than it not being bad for AI companies. Put another way, our human intelligence permits us to be selfish, capricious, devious, and even cruel, as our consciousness does battle with our feelings and instincts. Even when builders use distilled fashions from companies like OpenAI, they price far less to run, are inexpensive to create, and, subsequently, generate less revenue. Prevents the present coverage from deviating too far from the original mannequin. Policy (πθπθ): The pre-educated or SFT'd LLM. Efficient reward modeling: Using a smaller reward mannequin and distilling it into the policy. Using GRPO instead of PPO: Reducing computational requirements. Efficiency: By eliminating the critic community, GRPO reduces memory and compute necessities. Simplicity: GRPO is less complicated to implement and perceive in comparison with PPO.
Last week, Free DeepSeek v3 challenged conventional knowledge in AI. DeepSeek can answer questions, resolve logic problems, and write computer programs on par with different chatbots, according to benchmark exams utilized by American AI corporations. Companies can combine it into their merchandise with out paying for usage, making it financially attractive. The case for this release not being dangerous for Nvidia is even clearer than it not being bad for AI companies. Put another way, our human intelligence permits us to be selfish, capricious, devious, and even cruel, as our consciousness does battle with our feelings and instincts. Even when builders use distilled fashions from companies like OpenAI, they price far less to run, are inexpensive to create, and, subsequently, generate less revenue. Prevents the present coverage from deviating too far from the original mannequin. Policy (πθπθ): The pre-educated or SFT'd LLM. Efficient reward modeling: Using a smaller reward mannequin and distilling it into the policy. Using GRPO instead of PPO: Reducing computational requirements. Efficiency: By eliminating the critic community, GRPO reduces memory and compute necessities. Simplicity: GRPO is less complicated to implement and perceive in comparison with PPO.
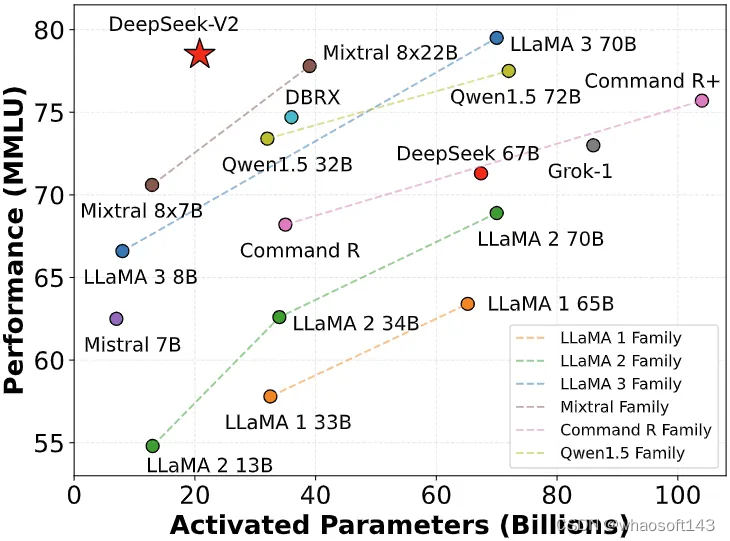 The AUC values have improved compared to our first attempt, indicating only a limited amount of surrounding code that needs to be added, but more analysis is needed to establish this threshold. Over time, we now have seen corporations evolve how they send information to foreign nations. It’s the telegraph over again. At solely $5.5 million to practice, it’s a fraction of the price of fashions from OpenAI, Google, or Anthropic which are sometimes within the tons of of thousands and thousands. If China cannot get millions of chips, we'll (a minimum of briefly) reside in a unipolar world, where only the US and its allies have these fashions. For this newsletter particularly, I suggest putting some time aside as now we have a ton of fabric! So I spent some time researching current literature that might clarify the reasoning, and potential options to those problems. Here, we investigated the effect that the mannequin used to calculate Binoculars rating has on classification accuracy and the time taken to calculate the scores. Use RL (e.g., PPO, GRPO) to advantageous-tune the model to maximize the reward model's scores. Prompt engineering: Carefully designing prompts to guide the model's behavior.
The AUC values have improved compared to our first attempt, indicating only a limited amount of surrounding code that needs to be added, but more analysis is needed to establish this threshold. Over time, we now have seen corporations evolve how they send information to foreign nations. It’s the telegraph over again. At solely $5.5 million to practice, it’s a fraction of the price of fashions from OpenAI, Google, or Anthropic which are sometimes within the tons of of thousands and thousands. If China cannot get millions of chips, we'll (a minimum of briefly) reside in a unipolar world, where only the US and its allies have these fashions. For this newsletter particularly, I suggest putting some time aside as now we have a ton of fabric! So I spent some time researching current literature that might clarify the reasoning, and potential options to those problems. Here, we investigated the effect that the mannequin used to calculate Binoculars rating has on classification accuracy and the time taken to calculate the scores. Use RL (e.g., PPO, GRPO) to advantageous-tune the model to maximize the reward model's scores. Prompt engineering: Carefully designing prompts to guide the model's behavior.
Cerebras Systems has wrote an article on semiconductor manufacturing by attaining viable yields for wafer-scale processors regardless of their massive dimension, challenging the longstanding belief that larger chips inherently endure from decrease yields. Yuge Shi wrote an article on reinforcement learning ideas; particularly ones which might be used in the GenAI papers and comparability with the methods that DeepSeek has used. I am protecting a single article today technically with RLHF and there's a ebook afterwards that talks in regards to the RLHF. The ebook begins with the origins of RLHF - both in recent literature and in a convergence of disparate fields of science in economics, philosophy, and optimal control. We then set the stage with definitions, problem formulation, knowledge assortment, and different frequent math used within the literature. Upon finishing the RL training part, we implement rejection sampling to curate excessive-high quality SFT information for the ultimate model, where the professional fashions are used as knowledge generation sources. Jailbreaks, which are one kind of immediate-injection assault, allow people to get across the security systems put in place to limit what an LLM can generate. SMOL-GPT is a PyTorch implementation for training your individual small LLM from scratch. Access to intermediate checkpoints throughout the base model’s training process is offered, with utilization subject to the outlined licence terms.
Curriculum learning: Gradually increasing the issue of duties throughout coaching. DeepSeek-R1, released in January 2025, focuses on reasoning tasks and challenges OpenAI's o1 model with its advanced capabilities. But Sampath emphasizes that Deepseek free’s R1 is a particular reasoning model, which takes longer to generate answers but pulls upon extra advanced processes to attempt to provide better outcomes. While OpenAI's o1 maintains a slight edge in coding and factual reasoning tasks, Free DeepSeek online-R1's open-supply entry and low prices are interesting to users. Intel/AMD CPUs: Similarly, multi-core CPUs are bought with subsets of cores enabled, depending on defect distribution during manufacturing. Yield in chip manufacturing is dependent upon defect rates and the flexibility to tolerate defects. They lucked out, and their completely optimized low-degree code wasn’t truly held again by chip capacity. Efficient implementation: Optimizing code for higher hardware utilization. AI fashions, it is comparatively straightforward to bypass DeepSeek’s guardrails to jot down code to assist hackers exfiltrate data, ship phishing emails and optimize social engineering attacks, in keeping with cybersecurity firm Palo Alto Networks.
- 이전글CBD Vape Oil 25.03.19
- 다음글روثلس - Ruthless - نكهات روثلس - روثلس عنب - روثلس عنب ايس 25.03.19
댓글목록
등록된 댓글이 없습니다.
